- 벡터: 여러 개의 숫자가 모여서 하나의 개념을 표현하는 단위
- 임베딩: 텍스트는 컴퓨터가 이해 x => 토큰을 수치화된 벡터로 변환하는 과정
1. 빈도 기반 벡터화
1) 공동작업
- 토큰화
Kiwi()
kiwi.tokenize(text)
kiwi = Kiwi()
# Kiwi 토큰화(명사, 동사, 형용사만 추출)
def tokenize_kiwi(text):
tokens = kiwi.tokenize(text)
return [token.form for token in tokens if token.tag.startswith(('N', 'V', 'A', 'X'))] # 명사(N), 동사(V), 형용사(A)만 추출
# 문장별 토큰화해서 리스트로 저장
tokenized_docs = [" ".join(tokenize_kiwi(doc)) for doc in documents] # 각 토큰은 ' ' 로 구분
print(tokenized_docs)
2) BOW: 빈도기반 벡터화
개념: 각 문장에서 등장하는 단어들을 하나의 주머니에 담고, 각 단어의 등장 횟수를 카운트한 후 이를 문장에 대한 벡터로 사용
한계: 단어의 순서, 원래의 의미, 맥락은 파악 할 수 없다.
- BOW 벡터화
CountVectorizer()
bow_vectorizer.fit_transform(tokenized_docs): 벡터화
bow_vectorizer.vocabulary_: 벡터화 결과 출력
pd.DataFrame: 데이터프레임 출력
# 기본값은 글자 2개 이상만 카운트
bow_vectorizer = CountVectorizer()
X = bow_vectorizer.fit_transform(tokenized_docs)
# 결과 출력
print("Vocab", bow_vectorizer.vocabulary_)
# DataFrame 변환 및 출력 (BOW)
bow_df = pd.DataFrame(X.toarray(), columns=bow_vectorizer.get_feature_names_out())
display(bow_df)

3) TF-IDF 벡터화
BOW: 자주 등장하는 단어가 영향을 주고, 단어의 중요도를 반영하지 않는다.
TF-IDF: 등장횟수 대신 단어의 중요도를 반영
TF: 얼마나 한 문서에 자주등장하는지
IDF: 특정 단어가 전체문서에서 얼마나 희귀한지
- 코드
TfidVectorizer(): 벡터화
tfidf_vectorizer.fit_transform(tokenized_docs): 벡터화
tfidf_vectorizer.vocabulary_: 단어 사전 출력
# 기본값은 글자 2개 이상만 카운트
tfidf_vectorizer = TfidfVectorizer()
X = tfidf_vectorizer.fit_transform(tokenized_docs)
# 단어 사전 출력
print("Vocabulary (단어 사전):", tfidf_vectorizer.vocabulary_)
# 벡터화 결과
tfidf_df = pd.DataFrame(X.toarray().round(3), columns=tfidf_vectorizer.get_feature_names_out())
tfidf_df

2. 분포 가설 방식: Word2Vec
- 비슷한 문맥에서 자주 등장하는 단어들이 유사한 벡터를 가지도록 학습하는 임베딩 기법
- 빈도 기반 방식과 비슷하게
데이터 전처리: 불용어처리, 토큰화를 해준다
Word2Vec 학습 두 가지 방법:
CBOW: 주변단어 -> 중심 단어 예측
Skip-gram: 중심단어 -> 주변 단어 예측
1) cbow 학습
Word2Vec(sentences=token_data, vector_size=100, window=5, min_count=5, workers=4, sg=0)
model_cbow = Word2Vec(sentences=token_data, vector_size=100, window=5, min_count=5, workers=4, sg=0) # CBOW
model_cbow.wv.most_similar("한석규", topn=20)): Word2Vec 모델을 사용해서 '한석규와' 가장 비슷한 단어 20개를 출력
print(model_cbow.wv.most_similar("한석규", topn=20))

model_cbow.wv['한석규']: 한석규라는 단어의 벡터 표현을 가져오는 코드
# 한석규 벡터
model_cbow.wv['한석규']
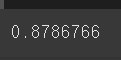
코사인 유사도
model_cbow.wv.similarity('한석규', '안성기')
# 코사인 유사도
model_cbow.wv.similarity('한석규', '안성기')
2) skip_gram 학습
model_skip = Word2Vect()
model_skip = Word2Vec(sentences=token_data, vector_size=100, window=5, min_count=5, workers=4, sg=1) # skip_gram
- model_skip.wv.most_similar("한석규")
Word2Vec 모델을 사용해서 '한석규와' 가장 비슷한 단어 20개를 출력
print(model_skip.wv.most_similar("한석규"))

# 한석규 벡터
model_skip.wv['한석규']
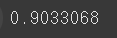
- 코사인 유사도 검사: model_skip.wv.similarity('한석규', '안성기')
# 코사인 유사도
model_skip.wv.similarity('한석규', '안성기')